I recently spent a bunch of optimizing an LSB Radix Sort in Rust. This post outlines some different memory management techniques.
Vector Per Bin
When using bytes as digits, you keep 256 vectors and append appropriately while shuffling elements. The obvious optimization is having an object pool for vector reuse.
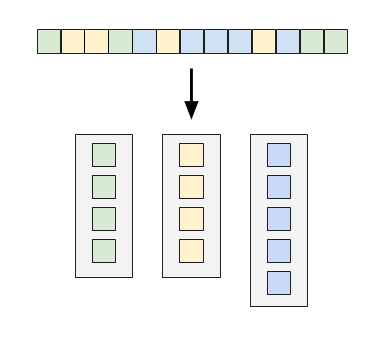
This technique is used by the radix sort in the Timely Dataflow repo. The Timely version makes the initial vector capacity equal to the page size (4 kB). There is a performance hit on small input vectors where most of the bins sit near-empty. My (unsubstantiated) guess is that the spread of data makes the CPU's memory prefetching ineffective.
Pre-Shuffle Histogram
Before shuffling elements, compute a histogram over the bytes and build a prefix sum from that. This prefix sum array gives you the next write position for each bin, which you update as you pack elements directly to a single output vector.
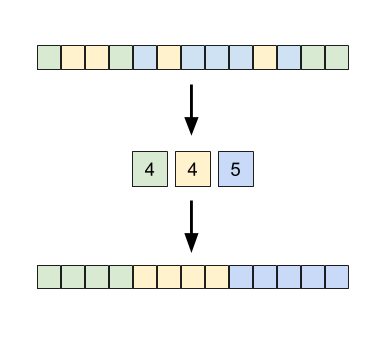
An obvious optimization is pouring back-and-forth between your input and a scratch vector for each shuffle step. (So with a u32 element being sorted per-byte, you would go input-to-scratch, scratch-to-input, input-to-scratch, scratch-to-input and then return input as your final result). This requires O(n) space for the scratch area.
Something not obvious is that efficiently computing byte histograms is hard on modern CPUs. It was the most expensive part of my implementation, taking far more time than the multiple passes of element shuffling. There is a good technical discussion on the RealTime Data Compression blog. Of particular note is the explanation by Nathan Kurz on how speculative loads are the culprit.
Two optimization techniques for histogram calculation are shown here. It uses four separate accumulators for the histogram loop, combining the arrays afterwards for a final result. (This is a common technique for reducing contention). The loop also does an explicit prefetch (the "cache" variable) in lieu of using prefetch intrinsics. I found that explicit prefetching worked for Rust too, giving a modest but measurable bump in sort throughput.
Memory Map Craziness
This super cool technique is from "Faster Radix Sort via Virtual Memory and Write-Combining".
You make an anonymous memory mapping that holds n*sizeof(n)*256 bytes. All bins are big enough to hold all elements! The magic is that Linux won't actually allocate the memory until you touch each backing page, at which point a page fault causes the kernel to spring in to action.
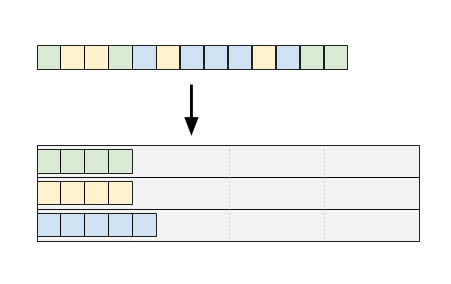
I sorted a billion u32 values (4 GB) on my desktop with 16 GB of RAM while mmapping 1 TB of virtual memory space using this technique.
For this to work, you must either enable memory overcommit in the Linux or pass
libc::MAP_NORESERV when doing the mmap. Otherwise it won't let
you do a 1 TB allocation.
I got this working but my own implementation was not particularly fast.
Software Write Combining
I tried several different implementations for SWC, but I was unable to increase overall sort throughput. The extra branching for managing SWC seems to wash out the gains for being cache-friendly in the the single busy core case. Perf_events did indicate a massive reduction in L3 cache misses, from ~50% to ~5%. I think it's worth further investigating SWC performance when all cores are pegged doing work.